This article describes why Beike chose Apache APISIX as the API gateway at the beginning, and some experiences in the process of using it.
My name is Hui Wang, and I am responsible for the development of the API gateway system at Beike. Beike uses Apache APISIX as the API gateway for the production system. It handles over 100 million production traffic every day, with excellent performance and stability. It happens that Apache APISIX has just joined the Apache incubator. In addition to congratulations, I would like to share why Beike chose Apache APISIX at the beginning and some experiences in the process of using it.
Choose Kong or Apache APISIX#
For the technical requirements of the gateway, the first is to have good performance and be able to support the access of large traffic, and the second is to be stable without problems.
The principle of model selection is to reconstruct a more stable version based on or learn from open source projects, which can ensure access to larger traffic. After evaluating the pros and cons, I communicated the idea with the leader, and decided to start it after getting the leader's affirmation. At this time, the first thing that comes to mind is Kong, the famous open source gateway. So I went to the official website to browse and read some surrounding articles. The first impression is that this project is very good, it can meet most of the needs of users, and the performance is stable, that's it. I cloned the code happily and began to read it. After a long time, I was still confused. Think about it, Kong can provide so many functions, and the complexity of its code can be imagined.
At this time, several questions appeared in my mind. How long can I chew down Kong by myself? And then how long does it take to build a project that suits you? There are so many functions I need?
Just a few days ago, the API gateway Apache APISIX version 0.5 was released. I took a look with an understanding mentality and found that it was an open source project jointly developed by the academy student and Wen Ming. With the guarantee of two technical bigwigs, I really wanted to try it out. .
With the attitude of giving it a try, I started to approach Apache APISIX. Due to the short open source time, the supported functions are limited, but basic functions such as dynamic load balancing, circuit breaker, identity authentication, speed limit, etc. have been implemented. At the same time, the amount of code is not very large, which reduces the cost of learning. At this point, PK lost Kong. So on the whole, Apache APISIX is more suitable for my current situation, to meet my initial functional planning, and I don't need to consider how to deal with the unneeded functions.
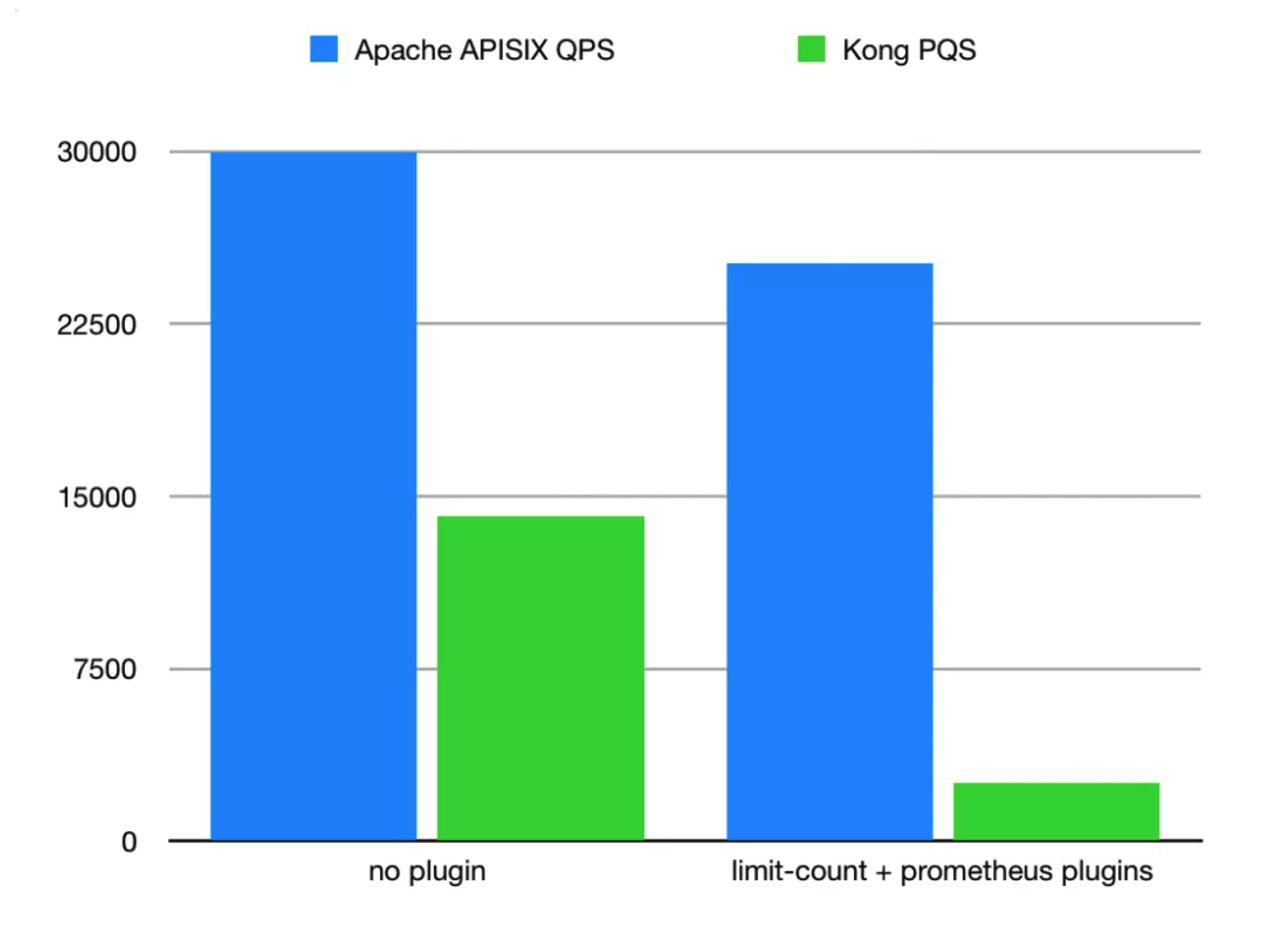
The most critical question, how is the performance of the open source time so short? Looking at the comparison of the stress test data in the same environment, Apache APISIX completely exploded Kong, although this is not fair. After all, Kong is a behemoth, but for my production environment, they are the same. According to the performance test report of Apache APISIX, a single-core CPU can reach 24k QPS, while the latency is only 0.7 milliseconds.
In the end, I chose Apache APISIX for the following reasons:
- On the premise that it can meet the needs of the project, the learning cost of Apache APISIX is low
- Kong has a huge amount of code, and later maintenance will also bring difficulties
- Apache APISIX authors are often active in the OpenResty community with guaranteed code quality
- The most important point is to have contact with the author, and you can communicate quickly if you have any questions
The reasons for the APISIX official website are shown in the following figure:

What capabilities can Apache APISIX provide#
- Hot Updates and Hot Plugins
- Dynamic load balancing
- Active and passive health detection
- Circuit Breaking
- Authentication
- Current limit and speed limit
- gRPC protocol conversion
- Dynamic TCP/UDP, gRPC, websocket, MQTT broker
- Dashboard
- Prohibited and Permitted List
- Serverless
Apache APISIX has been released nearly ten versions, and it supports far more functions than these. The architecture diagram is drawn according to the business situation, as follows:
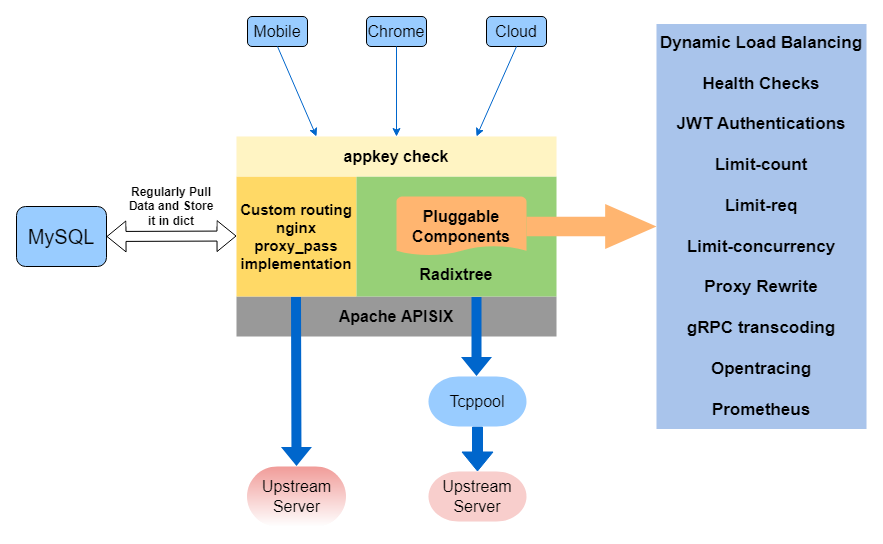
Integrating APISIX Process#
After a few days of code reading, I have a certain understanding of Apache APISIX, but the first problem arises: I have no experience in developing based on open source projects before. How to do it? I created three branches locally, one Apache APISIX branch points to the upstream open source repository, dev is used for regular business iteration, and the master branch is used for online upgrades.
After two weeks of typing on the keyboard, my "Little King Kong" finally has some appearance. It's time to see how fast it runs and whether it saves fuel. That's how the stress test began. The service is deployed on Tencent Cloud with 8 Core and 32 GB emory. The upstream is a real online production environment, so it cannot be pressed too hard. The performance report is as follows:
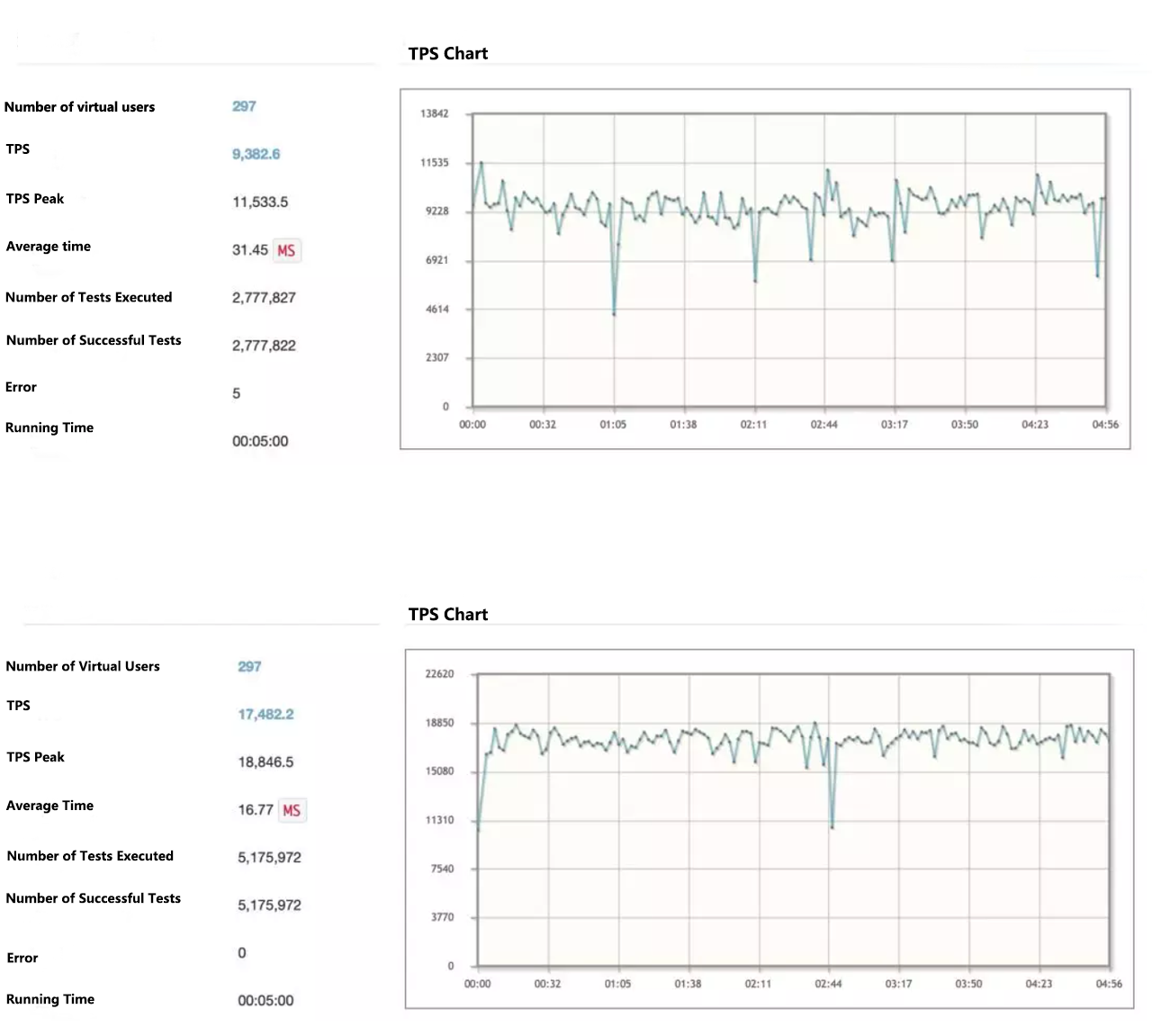
Performance report summary: The interface time consumption is reduced by 47%, no errors are generated, and the stability is improved. The TPS peak value is increased by 82%, no errors are generated, and the stability is improved.
The development environment is no problem, and we start to study online deployment. Apache APISIX supports various installation methods: Docker, RPM Package, Luarocks and Source Code. However, the online environment does't allow anything to be installed, and the code can only be placed in a fixed path. Many features supported by Apache APISIX are based on OpenResty 1.15.8. What should I do? After compiling, put it in the code repository, compile it according to the specified directory, and you cannot use the static binding of pcre, it takes a day or two to get it done. Adjusting the load began to grayscale, and it took a few weeks from 2% traffic to full volume, but fortunately everything went smoothly.
After several weeks of observation, the online service is very stable. Many functions of Apache APISIX 0.5 must be implemented through API interface calls. The request parameters are prone to syntax errors, and there is no intuitive and convenient page. Another point is that my business scenario needs to have the function of probing upstream services. It's such a coincidence that Apache APISIX version 0.7 has been released, and version 0.7 supports console and upstream service exploration. It's really good news for everyone, upgrade.
The Apache APISIX branch is easy to upgrade to 0.7, how do I merge the code? The code changes of the two versions are very large. Try to merge them first. There are too many conflicts, and the rhythm is dead. The ordinary method of resolving conflicts is unrealistic. There will be hidden bugs when you shake your hands in so many places. Is there no efficient way? I searched and found the shortcut methods git checkout --ours and git checkout --theirs (search for yourself if you haven't used it), and completed the upgrade from APISIX 0.5 to 0.7 in a few minutes. Of course, this is also due to the robustness of APISIX code, I only need to add business plug-ins, completely zero coupling.
Apache APISIX 0.7 version provides a console, no need to spell json anymore. I quickly tested the health detection function. There was no problem at first, and I could clearly perceive the status of the upstream service. However, when I observed the logs of the upstream service, I found that after several starts and stops, the frequency of the health detection function seems to be faster. It should be that there is a bug in the health check. Simply read the relevant code and find that the checker for each route created is not globally unique, but one is created for each work. The name can be guaranteed to be globally unique. Although the changes are small, a PR was submitted quickly.
I upgraded the online business APISIX to 0.7, and then observed the service resource usage. After all, it was a larger version, and I didn’t feel it for the first few hours, which was similar to the previous 0.5. I'll take a look at it again when I get off work. It seems that the memory resource usage is not right. The 0.5 version has been relatively stable, but the 0.7 version seems to have leaks. Because the memory usage is growing very slowly, I decided to observe it for another night. The next day, I compared the monitoring data, determined that there was a memory leak, and quickly rolled back to the previous version. I gave feedback to the students about the problem. According to the scenario I described, I found the problem through stress testing. It was a problem with radixtree. The students released a new version of radixtree. I upgraded the dependencies, and then performed stress testing, but the problem did not recur.
Going online again, Apache APISIX 0.7 version still gave me some surprises. The routing dependency used in Apache APISIX 0.5 version was libr3, while Apache APISIX 0.7 used radixtree instead, which has better performance, cpu usage and memory than before. All have declined. In Apache APISIX 0.5, the single-work cpu usage is 1-10%, and the memory is 0.1%. In Apache APISIX 0.7, the single-work cpu usage is reduced to 1-2%, and the memory is less than 0.1%, which is excellent.
Future Plan#
Apache APISIX has been running online for two months, and there has been no online failure. This is the beginning, and we can do a lot in the future to show more capabilities to service providers. The gateway provides not only a reverse proxy, but also helps some teams that do not have more energy to develop functions to ensure service stability, including services such as current limiting, circuit breaker, monitoring, and access platforms. Finally, I would like to thank the two big guys for providing such excellent products, and also thank the Apache APISIX community for the iterative functions contributed.
Now the daily traffic of the gateway has exceeded 100 million, and there is no performance problem. If the traffic can reach one billion, I will share Apache APISIX and my way forward in the future. Welcome everyone to pay attention.