本文讲述了贝壳找房当初为什么选择 Apache APISIX 作为 API 网关,以及使用过程中的一些心得。
我是王辉,在贝壳找房负责 API 网关系统的开发,贝壳找房使用 Apache APISIX 作为生产系统的 API 网关,每天处理过亿的生产流量,性能优异,而且很稳定。正好 Apache APISIX 刚刚加入 Apache 孵化器,除了恭喜之外,我想来分享下贝壳找房当初为什么选择 Apache APISIX,以及使用过程中的一些心得。
选择 Kong 还是 Apache APISIX#
对于网关的技术要求,一是要性能好,能够支撑大流量的接入,二是要稳定,不能出问题。
选型的原则就是基于或者借鉴开源项目重构一个更加稳定的版本,能够保证接入更大的流量,刚开始的流量还少,做这样的大动作是完全可以接受的。评估完利弊后和领导沟通了一下想法,得到领导的肯定后就决定搞起,这时脑海想的第一个就是 Kong 了,大名鼎鼎的开源网关。于是就去官网浏览了一番,周边文章也看了些,第一印象就是这个项目很不错,能够满足用户的大多数需求,性能还稳定,就是它了。兴高采烈地 clone 了代码开始阅读起来,一天两天若干天过去了,还是一头雾水的样子,想想也是,Kong 能提供这么多的功能,其代码的复杂度可想而知。
这时几个问题出现在我的脑海里,我一个人多久能啃下来 Kong 呢?然后还要构建一个适合自己的项目,又需要多久呢?还有就是这么多的功能我都需要么?
刚好那几天 API 网关 Apache APISIX 0.5 版本发布了,抱着了解的心态去看了一眼,发现是院生和温铭一起搞的开源项目,有两位技术大佬的背书,让我不禁想试试看。
抱着试一试的态度开始走近 Apache APISIX,由于开源时间较短所以支持的功能有限,但是像动态负载均衡、熔断、身份认证、限速等等这些基本功能都已实现。同时代码量也不是很大降低了学习成本,在这一点上 PK 掉了 Kong。所以综合来看 Apache APISIX 更适合我当前的状况,满足我初期的功能规划,也不用考虑不需要的功能怎么处理问题了。
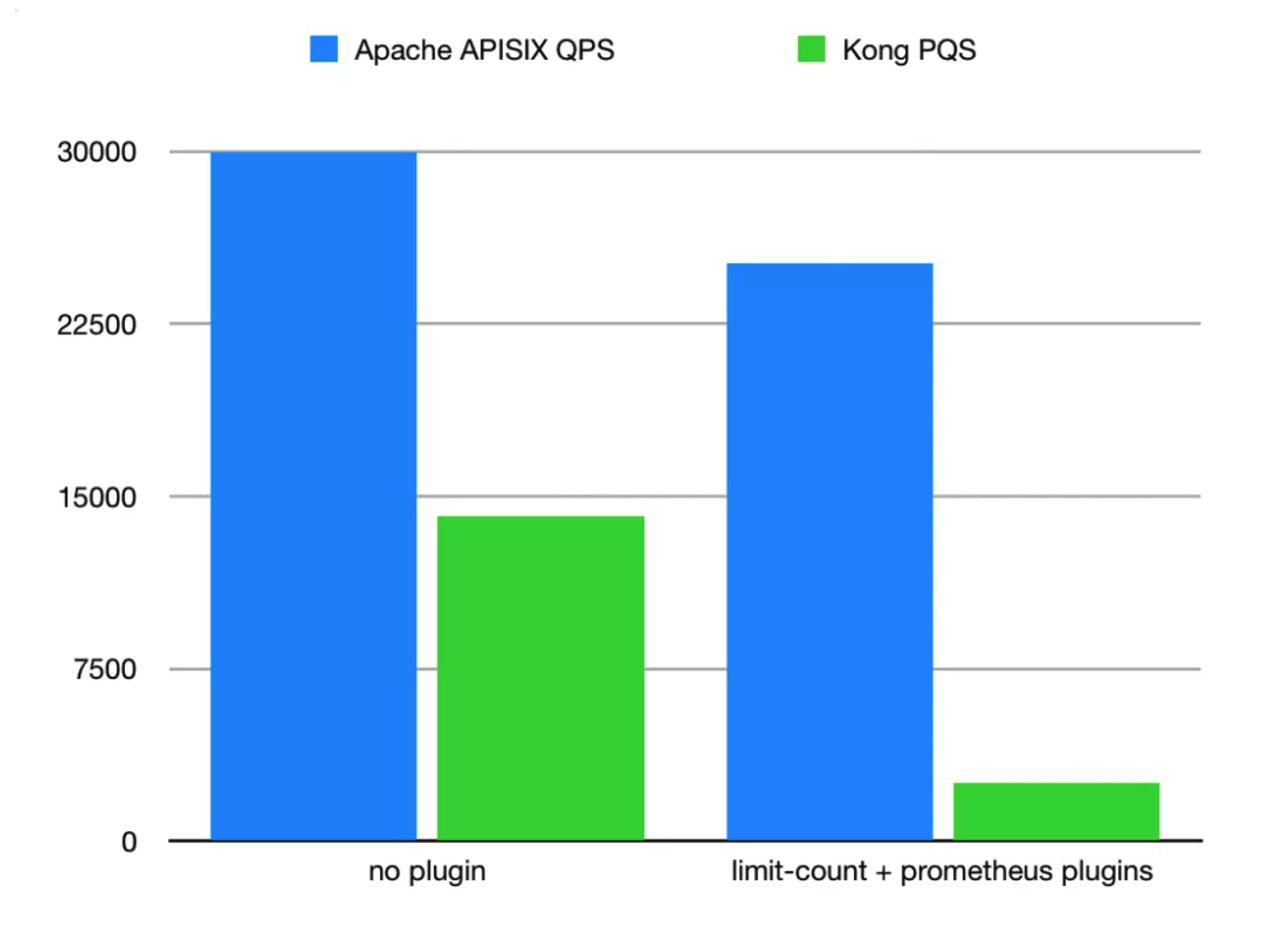
最关键的问题,开源时间这么短,性能怎么样?看了相同环境的压测数据对比,Apache APISIX 完爆 Kong,虽然这样不太公平,毕竟 Kong 是个庞然大物,但对于我的生产环境来说,它俩是一样的。根据 Apache APISIX 的性能测试报告,单核 CPU 可以达到 24k QPS,同时延时只有 0.7 毫秒。
最终选择了 Apache APISIX,我的理由如下:
- 在都能满足项目需求的前提下,Apache APISIX 学习成本低
- Kong 的代码量庞大,后期维护也会带来难度
- Apache APISIX 作者经常活跃于 OpenResty 社区,代码质量有保证
- 最重要的一点就是接触过作者,有什么问题都可以快速的沟通
官网的理由如下图所示:

Apache APISIX 能提供哪些能力#
- 热更新和热插件
- 动态负载均衡
- 主动和被动健康检测
- 熔断器
- 身份认证
- 限流限速
- gRPC 协议转换
- 动态 TCP/UDP、gRPC、websocket、MQTT 代理
- 控制台
- 黑白名单
- Serverless
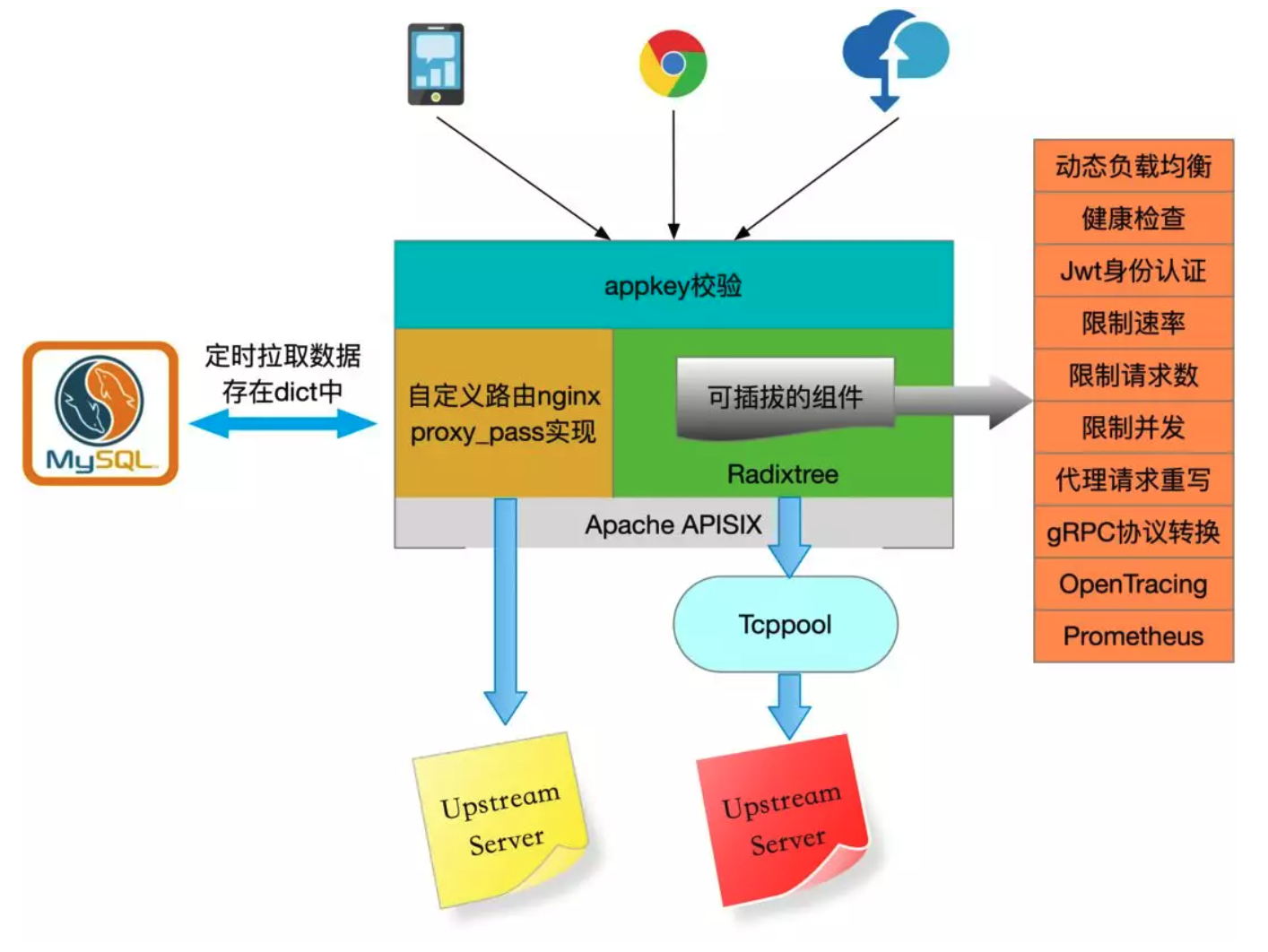
Apache APISIX 已经发布了接近十个版本了,它所支持的功能远不止这些了。结合业务情况绘制了架构图,如下:
集成 APISIX 的点点滴滴#
经过几天的代码阅读,对 Apache APISIX 有了一定的了解了,但第一个问题出现了:之前没有基于开源项目开发的经验,一方面要做业务需求迭代,一方面还要升级开源项目,怎么搞呢?我在本地创建了三个分支,一个 Apache APISIX 分支指向上游开源仓库,dev 用来常规的业务迭代,而 master 分支用来上线升级。
在键盘上敲打了两周,我的“小金刚”终于有些模样了,该看看它跑的有多快、省不省油了,就这样压测开始了。服务部署在 8CPU 32G 内存的腾讯云上面了,上游是真实的线上生产环境,因此不能压的太狠,性能报告如下:
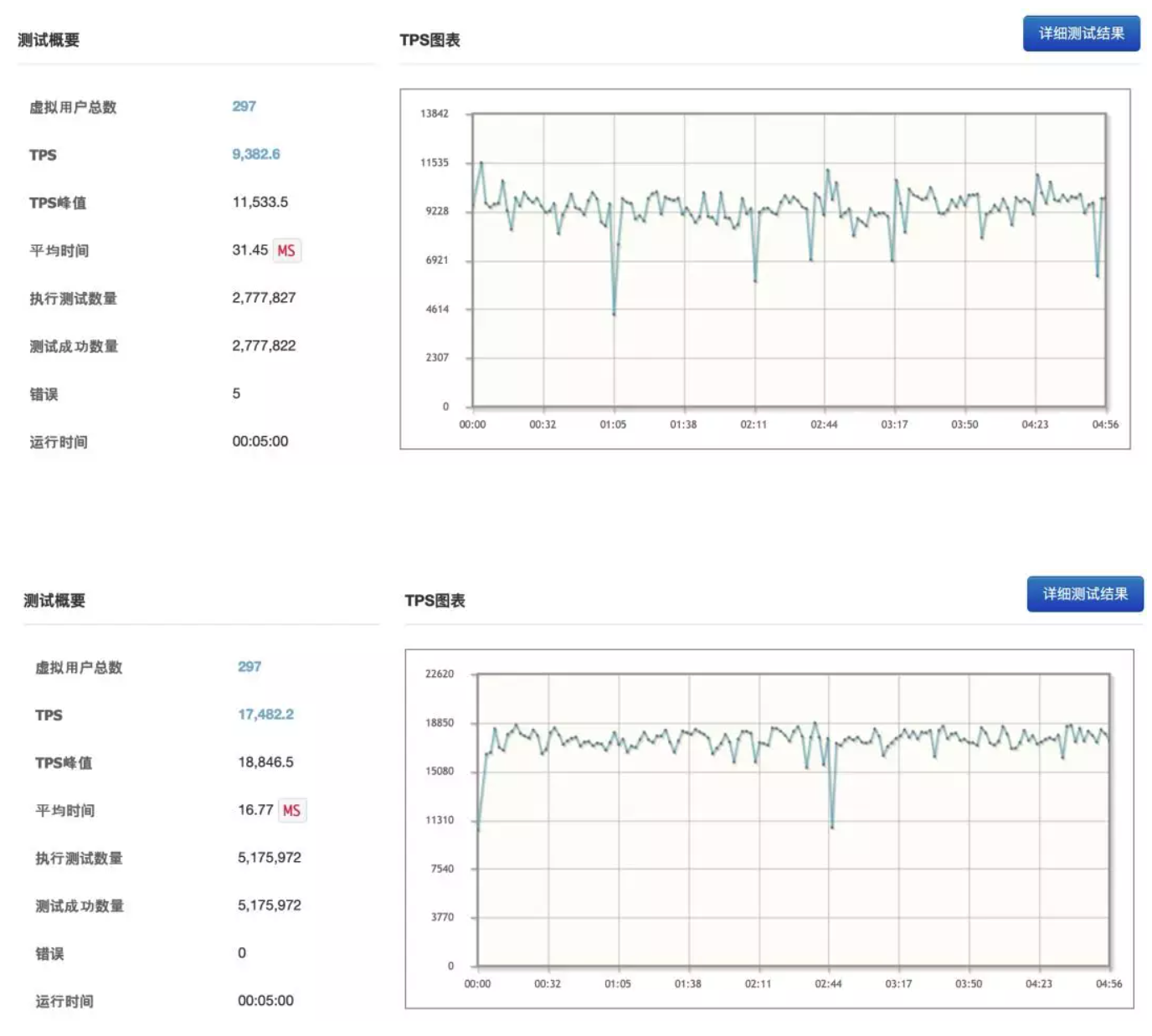
性能报告小结:接口耗时减少了 47%,没有错误产生稳定性有所提升,TPS 峰值提升了 82%,没有错误产生,稳定性有所提升。
开发环境没问题了,开始研究线上部署。Apache APISIX 支持各种安装的方式:docker、rpm 包、Luarocks 和源码。但是线上环境不让安装任何东西,代码只能放到固定的路径中,Apache APISIX 支持的很多特性都是基于 OpenResty 1.15.8 的,咋搞呢?编译完了放在代码仓库中吧,按照指定的目录进行编译,而且不能用 pcre 的静态联编,折腾了一两天才搞定。调整负载开始灰度,从 2% 的流量到全量经历了几周,好在一切顺利。
经过几周的观察线上服务很稳定,Apache APISIX 0.5 版本的很多功能都是得用通过 API 接口调用实现的,请求参数比较容易出现语法错误,没有页面来的直观方便,还有一点就是我的业务场景需要有对上游服务的探活功能。就是这么巧 Apache APISIX 0.7 版本发布了,0.7 版本支持了控制台和上游服务探活,真是个喜大普奔的好消息啊,升级。
Apache APISIX 分支升级到 0.7 很方便,我咋合并代码呢?两个版本代码改动非常大,先尝试一下合并,我的天啊,这冲突太多了,搞死的节奏啊,普通的解决冲突的方法不现实了,这么多处手一抖还会出现一下隐藏的 bug,有没有啥高效的方法呢?搜索了一下找到了快捷方法 git checkout --ours 和 git checkout --theirs(没用过的自行搜索哈),几分钟完成 APISIX 0.5 到 0.7 的升级,很痛快。当然这也是得益于 APISIX 代码的健壮,我只需要添加业务插件即可,完全零耦合。
Apache APISIX 0.7 版本提供了控制台了,不用再拼 json 了,舒服。赶紧测试一下自己关心的健康检测吧,一开始没什么问题,能够清晰的感知上游服务的状态,但我观察上游服务的日志发现,经过几次启停,健康检测功能探活的频率好像变快了,应该是健康检测有 bug,简单的阅读一下相关的代码,发现创建的每个路由的 checker 不是全局唯一的,而是每个 work 创建了一个,发现问题就好办了,创建的 work 都用一个 name 就能保证全局唯一了,虽然改动很小,但还是赶紧提交了一个 PR。
把线上业务 APISIX 升级到了 0.7,然后观察服务资源占用情况,毕竟是升级了较大的版本,头几个小时还没感觉,和之前 0.5 差不多。等下班时再看一眼,好像内存资源占用好像不太对,0.5 版本一直比较稳定,0.7 却好像有泄漏,因为内存的占用增长很慢,就决定再观察一晚上。第二天来对比了监控数据,确定是有内存泄漏,赶紧回滚到上一个版本。和院生反馈了一下问题,根据我描述的场景通过压测发现了问题所在,是 radixtree 的问题,院生发布了 radixtree 的新版本,我升级了一下依赖,然后在进行压测,没有复现问题,皆大欢喜。
再次上线,Apache APISIX 0.7 版本还是给了我一些惊喜的,之前 Apache APISIX 0.5 版本使用的路由依赖是 libr3,而 Apache APISIX 0.7 是换用了 radixtree,较之前有更好的表现,cpu 使用率和内存都有所下降,Apache APISIX 0.5 版本单 work 的 cpu 在 1-10%,内存 0.1%,Apache APISIX 0.7 版本单 work 的 cpu 使用率降低到 1-2%,内存也不足 0.1% 了,优秀。
未来规划#
Apache APISIX 在线上已经跑了两个月了,还未出现线上故障,窃喜。这才是开始,后续我们还能做很多东西,把更多的能力展现给服务方。网关提供的不仅仅只是反向代理,可以给一些没有更多精力去开发保证服务稳定功能的团队提供帮助,包括限流、熔断、监控等服务,还有接入的平台。最后感谢两位大佬提供了这么优秀的产品,也感谢 Apache APISIX 社区贡献出的迭代功能。
现在网关每日流量已经过亿,还没有什么性能问题,流量如果能达到十亿级,后续还会再分享一下 Apache APISIX 和我的前行之路,欢迎大家关注。