本文介绍了又拍云选择 Apache APISIX Ingress 后所带来公司内部网关架构的更新与调整,同时分享了在使用过程中的一些实践场景介绍。 作者陈卓,又拍云开发工程师,负责云存储、云处理和网关应用开发。
项目背景介绍#
目前市面上可执行 Ingress 的产品项目逐渐丰富了起来,可选择的范围也扩大了很多。这些产品按照架构大概可分为两类,一类像 k8s Ingress、Apache APISIX Ingress,他们是基于 Nginx、OpenResty 等传统代理器,使用 k8s-Client 和 Golang 去做 Controller。还有一类新兴的用 Golang 语言去实现代理和控制器功能,比如 Traefik。
又拍云最开始包括现在的大部分业务仍在使用 Ingress-Nginx,整体架构如下。
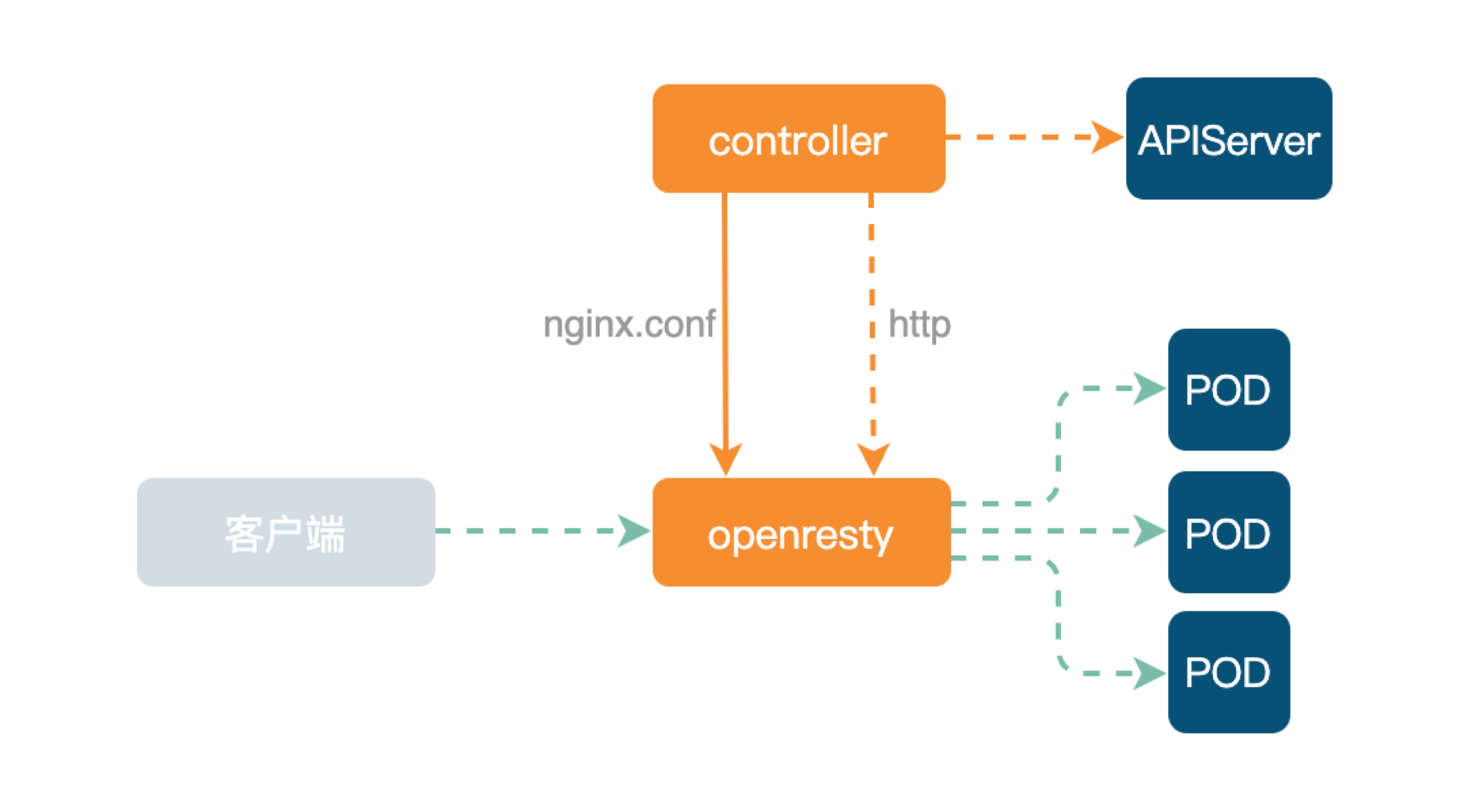
下层为数据面 OpenResty。上层 Controller 主要是监听 APIServer 的资源变化,并生成 nginx.conf 配置文件,然后 Reload OpenResty。如果 POD IP 发生变化,可直接通过 HTTP 接口传输给 OpenResty Lua 代码去实现上游 Upstream node 替换。
Ingress-Nginx 的扩展能力主要通过 Annotations 去实现,配置文件本身的语法和路由规则都比较简单。可以按照需求进行相关指令配置,同时也支持可拓展 Lua 插件,提高了定制化功能的可操作性。
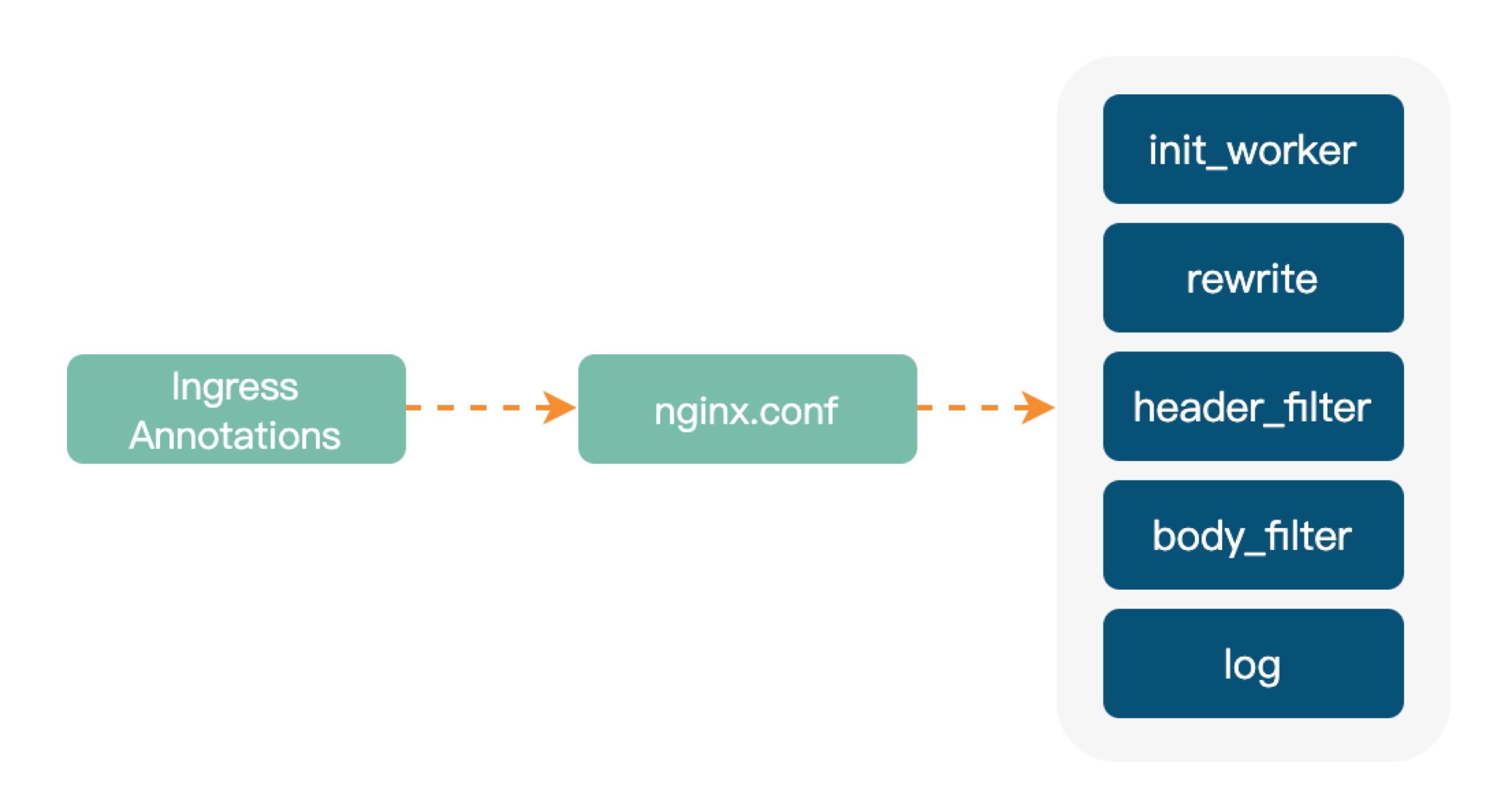
但 Ingress-Nginx 它也有一些缺点,比如:
- 开发插件时组件依赖复杂,移植性差
- 语义能力弱
- 任何一条 Ingress 的修改都需要 Reload,对长链接不友好
在维护现有逻辑时,上述问题造成了一定程度的困扰,所以我们开始寻找相关容器网关替代品。
调研阶段#
在替代 Ingress-Nginx 的选择中,我们主要考量了 Traefik 和 Apache APISIX Ingress。
Traefik 是云原生模式,配置文件极其简单,采用分布式配置,同时支持多种自动配置发现。不仅支持 k8s、etcd,Golang 的生态语言支持比较好,且开发成本较低,迭代和测试能力较好。但是在其他层面略显不足,比如:
- 扩展能力弱
- 不支持 Reload
- 性能和功能上不如 Nginx(虽然消耗也较低)
它不像 Nginx 有丰富的插件和指令,通过增加一条指令即可解决一个问题,在线上部署时,可能还需在 Traefik 前搭配一个 Nginx。
综上所述,虽然在操作性上 Traefik 优势尽显,但在扩展能力和运维效率上有所顾虑,最终没有选择 Traefik。
为什么选择 Apache APISIX Ingress#
内部原因#
在公司内部的多个数据中心上目前都存有 Apache APISIX 的网关集群,这些是之前从 Kong 上替换过来的。后来基于 Apache APISIX 的插件系统我们开发了一些内部插件,比如内部权限系统校验、精准速率限制等。
效率维护层面#
同时我们也有一些 k8s 集群,这些容器内的集群网关使用的是 Ingress Nginx。在之前不支持插件系统时,我们就在 Ingress Nginx 上定制了一些插件。所以在内部数据中心和容器的网关上,Apache APISIX 和 Nginx 的功能其实有一大部分都是重合的。
为了避免后续的重复开发和运维,我们想把之前使用的 Ingress Nginx 容器内网关全部替换为 Apache APISIX Ingress,实现网关层面的组件统一。
基于 Apache APISIX Ingress 的调整更新#
目前 Apache APISIX Ingress 在又拍云是处于初期(线上测试)阶段。因为 Apache APISIX Ingress 的快速迭代,我们目前还没有将其运用到一些重要业务上,只是在新集群中尝试使用。
架构调整#
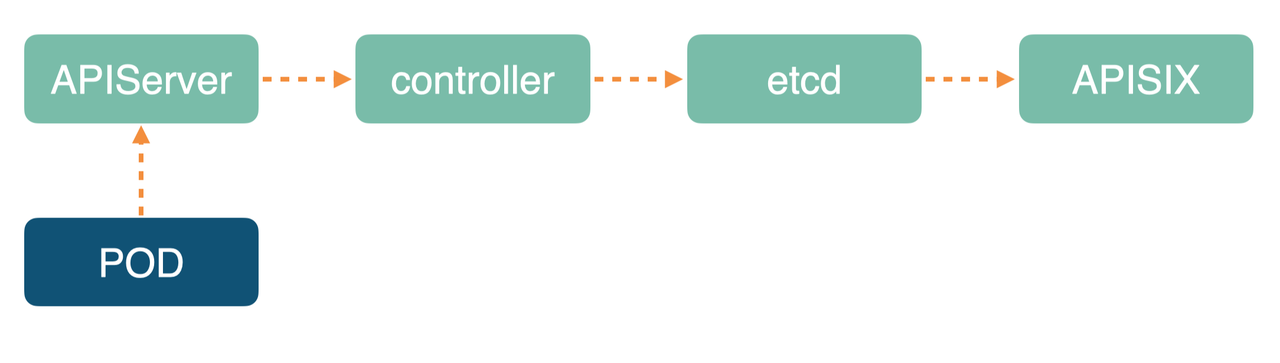
使用 Apache APISIX Ingress 之后,内部架构如下图所示。
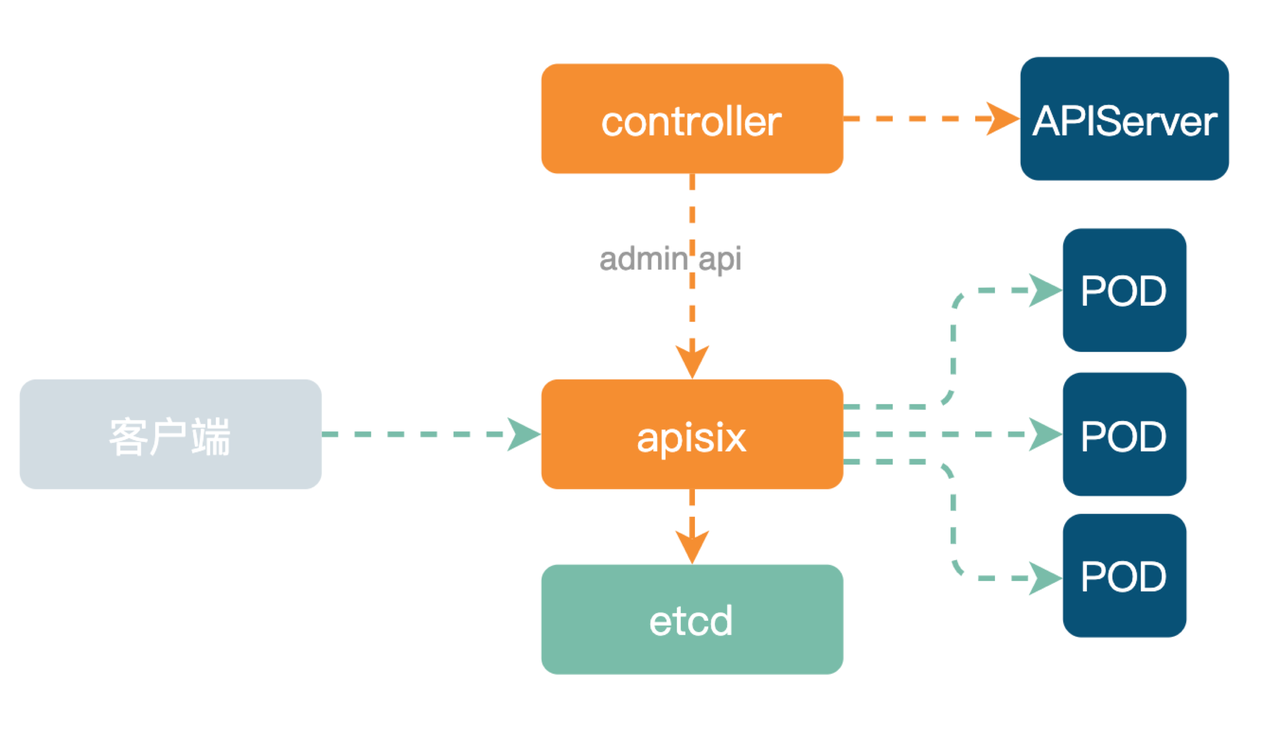
跟前面提到的 Ingress-Nginx 架构不一样,底层数据面替换成了 Apache APISIX 集群。上层 Controller 监听 APIServer 变化,然后再通过 etcd 将配置资源分发到整个 Apache APISIX 集群的所有节点。

由于 Apache APISIX 是支持动态路由修改,与右边的 Ingress-Nginx 不同。在 Apache APISIX 中,当有业务流量进入时走的都是同一个 Location,然后在 Lua 代码中实现路由选择,代码部署简洁易操作。而右侧 Ingress-Nginx 相比,其 nginx.conf 配置文件复杂,每次 Ingress 变更都需要 Reload。
Apache APISIX Ingress Controller#
Apache APISIX Ingress Controller 依赖于 Apache APISIX 的动态路由能力进行功能实现。它主要监控 APIServer 的资源变化,进行数据结构转换、数据校验和计算 DIFF,最后应用到 Apache APISIX Admin API 中。
同时 Apache APISIX Ingress Controller 也有高可用方案,直接通过 k8s 的 leader-election 机制实现,不需要再引入外部其他组件。
声明式配置#
目前 Apache APISIX Ingress Controller 支持两种声明式配置,Ingress Resource 和 CRD Resource。前者比较适合从 Ingress-Nginx 替换过来的网关控件,在转换成本上是最具性价比的。但是它的缺点也比较明显,比如语义化能力太弱、没有特别细致的规范等,同时能力拓展也只能通过 Annotation 去实现。

又拍云内部选择的是第二种声明配置——语义化更强的 CRD Resource。结构化数据通过这种方式配置的话,只要 Apache APISIX 支持的能力,都可以进行实现。

如果你想了解更多关于 Apache APISIX Ingress Controller 的细节干货,可以参考 Apache APISIX PMC 张超在 Meetup 上的分享视频。
功能提升#
效果一:日志层面效率提高#
目前我们内部有多个 Apache APISIX 集群,包括数据中心网关和容器网关都统一开始使用了 Apache APISIX,这样在后续相关日志的处理/消费程序时可以统一到一套逻辑。

当然 Apache APISIX 的日志插件支持功能也非常丰富。我们内部使用的是 Kafka-Logger,它可以进行自定义日志格式。像下图中其他的日志插件可能有些因为使用人数的原因,还尚未支持自定义化格式,欢迎有相关需求的小伙伴进行使用并提交 PR 来扩展当前的日志插件功能。

效果二:完善监控与健康检查#
在监控层面,Apache APISIX 也支持 Prometheus、SkyWalking 等,我们内部使用的是 Prometheus。
Apache APISIX 作为一个基本代理器,可以实现 APP 状态码的监控和请求等需求。但 Apache APISIX 的自身健康检查力度不是很好控制。目前我们采用的是在 k8s 里面部署一个服务并生成多个 POD,将这个服务同时应用于 Apache APISIX Ingress,然后通过检查整个链路来确定 Apache APISIX 是否健康。
使用 Apache APISIX Ingress 实践解决方案#
场景一:k8s 应用变更#
在使用 k8s 搭配 Apache APISIX Ingress 的过程中,需要做到以下几点:
- 更新策略的选用建议使用滚动更新,保证大部分 POD 可用,同时还需要考虑稳定负载的问题
- 应对 POD 启动 k8s 内部健康检查,保证 POD 的业务可用性,避免请求过来后 POD 仍处于不能提供正常服务的状态
- 保证 Apache APISIX Upstream 里的大部分 Endpoint 可用
在实践过程中,我们也遇到了传输延时的问题。POD 更新路径如下所示,POD Ready 后通过层层步骤依次进行信息传递,中间某些链路就可能会出现延时问题。正常情况下一般是 1 秒内同步完成,某些极端情况下部分链路时间可能会增加几秒进而出现 Endpoint 更新不及时的问题。
这种情况下的解决方案是,当更新时前一批 POD 变成 Ready 状态后,等待几秒钟再继续更新下一批。这样做的目的是保证 Apache APISIX Upstream 里的大部分 Endpoint 是可用的。
场景二:上游健康检查问题#
由于 APIServer 面向状态的设计,在与 Apache APISIX 进行同步时也会出现延时问题,可能会遇到更新过程中「502 错误状态警告」。像这类问题,就需要在网关层面对 Upstream Endpoint 进行健康检查来解决。
首先 Upstream Endpoint 主动健康检查不太现实,因为 Endpoint 太耗时费力。而 HTTP 层的监控检查由于不能确定状态码所以也不适合进行相关操作。
最合适的方法就是在网关层面基于 TCP 做被动健康检查,比如你的网络连接超时不可达,就可以认为 POD 出现了问题,需要做降级处理。这样只需在 TCP 层面进行检查,不需要触及其他业务部分,可达到独立操控。
场景三:mTLS 连接 etcd#
由于 Apache APISIX 集群默认使用单向验证的机制,作为容器网关使用 Apache APISIX 时,可能会在与 k8s 连接同一个 etcd 集群(k8s etcd 中使用双向验证)时默认开启双向认证,进而导致出现如下证书问题:
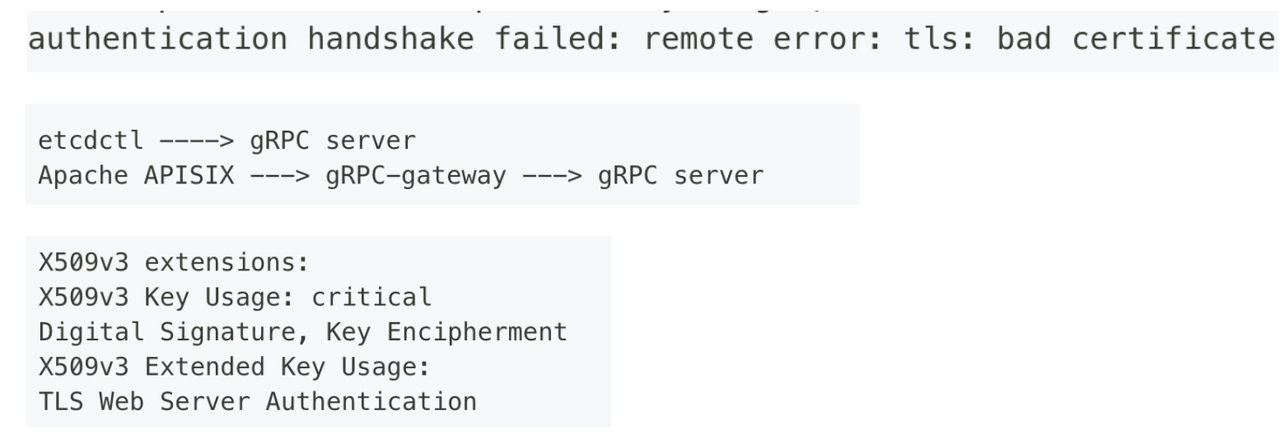
Apache APISIX 不是通过 gRPC 直接连接 etcd,而是通过 HTTP 协议先连接到 etcd 内部的 gRPC-gateway,再去连接真正的 gRPC Server。这中间多了一个组件,所以就会多一次双向验证。
gRPC-gateway 去连接 gRPC Server 的时候需要一个客户端证书,etcd 没有提供这个证书的配置项,而是直接使用 gRPC server 的服务端证书。相当于一个证书同时作为客户端和服务端的校验。如果你的 gRPC server 服务端证书开启了扩展(表明这个证书只能用于服务端校验),那么需要去掉这个扩展,或者再加上也可用于客户端校验的扩展。
同时 OpenResty 底层是不支持 mTLS 的,当你需要通过 mTLS 连接上游服务或 etcd 时,需要使用基于 apisix-nginx-module 去构建打过 patch 的 Openresty。apisix-build-tools 可以找到相关构建脚本。
未来期望#
虽然目前我们还只是在测试阶段应用 Apache APISIX Ingress,但相信在不久之后,经过应用的迭代功能更新和内部架构迁移调整,Apache APISIX Ingress 会统一应用到又拍云的所有容器网关内。